n8n Guardrails vs Human-in-the-Loop: When to Use Each
n8n guardrails catch rule violations automatically. HITL catches judgment calls. When to use each, and why production workflows need both.
By Iiro Rahkonen on
TL;DR: n8n guardrails and human-in-the-loop (HITL) are not interchangeable. Guardrails are automated rule checks, they catch profanity, PII, jailbreak attempts, and format violations at machine speed. HITL pauses the workflow for a human to judge tone, accuracy, and business context. The strongest production pattern runs guardrails before HITL so reviewers only see outputs that already pass the basic checks.
Community threads and YouTube tutorials treat "add guardrails" and "add human-in-the-loop" as two ways of saying the same thing. They are not. Guardrails enforce rules. HITL applies judgment. They operate at different layers, they fail in different ways, and they cost different amounts. Treating them as interchangeable is how you end up with a workflow that is either too rigid to help anyone or too unsupervised to trust.
Both belong in the same workflow. They sit a few nodes apart, doing fundamentally different jobs. This article explains what each one actually does, what work remains after each layer runs, and why the answer for most production n8n AI agent workflows is both, in sequence.
What n8n Guardrails Actually Do
The n8n Guardrails node enforces safety, security, and content policies on text. You can place it before an AI model to validate user input, or after the model to validate its output before downstream actions run. It operates in two modes.
Check Text for Violations. You select one or more guardrails from a built-in list and configure each. If any guardrail flags the text, the item routes to the Fail branch. Clean items continue down the Pass branch. This is the mode you use when the right response to a violation is "block, regenerate, or escalate."
Sanitize Text. A subset of guardrails (PII, URLs, Secret Keys, Custom Regex) can replace detected matches with placeholders like [EMAIL_ADDRESS] or [PHONE_NUMBER] and let the workflow continue with the cleaned text. Use this when you want the text to keep flowing but with sensitive content masked. Note that NSFW, Jailbreak, Topical, and Keyword guardrails are Check-mode only, they cannot sanitize.
Both modes are fully automated. No human involved. The node evaluates, decides, and acts the same way every time.
What the built-in guardrails cover
The node ships with eight guardrail types, split between pattern-based and LLM-based detection:
Pattern-based (deterministic, milliseconds):
- Keywords. Block specific terms or phrases. Useful for profanity lists, banned competitor mentions, or off-limits topics expressed as exact strings.
- PII detection. Detect personally identifiable information: credit card numbers, email addresses, phone numbers, US SSNs, and other configurable types. Available in both Check and Sanitize modes.
- URLs. Whitelist or blacklist domains. Catches outbound links to unapproved sites.
- Secret keys. Detects API key and credential patterns leaking into the text.
- Custom regex. User-defined regular expressions for anything the built-in detectors do not cover.
LLM-based (slower, seconds, calls a model):
- NSFW detection. Flags inappropriate or unsafe content using an LLM judgment.
- Jailbreak detection. Catches prompt-injection attempts trying to override system instructions. Most useful on user input before it reaches the agent.
- Topical alignment. Keeps the conversation inside a defined topic. For example, an AI support agent can be constrained to product topics and prevented from giving medical, legal, or financial advice.
The common thread: definable criteria, objective evaluation, and a right answer that does not change based on who the customer is or what happened last week.
A few things the Guardrails node does not cover, despite intuition: word/character limits, required disclaimer text, JSON-schema validation, and structural format checks are not built-in guardrail types. Those still belong in output parsers, Code/Set nodes, or Custom Regex (for the cases regex can express).
The economics favor high-volume checks
Pattern-based guardrails add milliseconds. LLM-based guardrails (NSFW, Jailbreak, Topical) take seconds because they call an LLM, but still far less than human review time and cost. Whether you process 50 messages a day or 50,000, the guardrail node behaves the same way at the same per-item cost. You cannot put a human reviewer in front of every message just to check for profanity. The math does not work. Guardrails make it unnecessary.
What Human-in-the-Loop Actually Does
HITL is structurally different from guardrails. Instead of applying a rule and continuing, the workflow pauses. It sends the AI output, along with whatever context the reviewer needs, to a human being and waits for a decision.
The reviewer might approve the output as-is. They might edit it before approving. They might reject it entirely and send it back for regeneration. They might escalate it to someone with more authority. The decision requires judgment that no rule can encode.
Where HITL catches what guardrails miss
- Tone appropriateness in context. The AI drafted a profanity-free response to a customer who just lost a family member. It opens with "Great news about your account." A guardrail will not flag that. A reviewer who sees the customer's recent tickets will.
- Factual accuracy. The AI stated the customer's policy covers water damage. Maybe the customer has the basic tier that excludes it. A guardrail has no access to account data. A reviewer does.
- Business decisions. The AI recommends a 20% discount to retain a churning customer. Is that the right number? This depends on lifetime value, current pipeline, and what the account manager thinks. No rule covers it.
- Creative quality. The AI wrote a response that is technically correct and policy-compliant. It is also generic and unhelpful. A guardrail has nothing to say about that.
- Novel situations. The customer asked something your workflow has never encountered. The AI output is ambiguous. No rule covers this. A human can navigate the grey area without needing a fluorescent vest.
The economics are different
HITL takes minutes, sometimes hours. It costs real human time. Doubling your message volume means doubling your reviewers or accepting longer queues. Use that time for judgment calls: tone, facts against account data, business decisions. Clear rules belong in the automated layer.
Where Guardrails Break Down
Guardrails are powerful within their scope. But that scope has hard edges.
They cannot judge tone in context. A guardrail cannot know that the customer you are responding to has submitted three complaints this week and is about to churn. Tone that works for a happy customer is a disaster for an angry one. Guardrails see text, not relationships.
They cannot detect plausible-but-fabricated facts. If your AI states "Your order shipped on March 12th," a guardrail has no way to verify that. The text is policy-compliant and potentially a complete hallucination. Catching this requires cross-referencing actual order data.
They cannot assess business appropriateness. The AI offers a full refund. Your policy says partial refunds only for this category. A guardrail checking for profanity and PII lets it through.
They create false confidence. When output passes a guardrail, it feels "verified." It has only been checked against the rules you defined. Everything else sailed through without examination.
Where HITL Is Overkill
Not everything needs a human. Profanity filtering, PII scrubbing, banned-keyword detection, jailbreak attempts, off-topic drift, leaked credentials, and competitor-mention rules are all guardrail-shaped checks.
A guardrail node handles them in milliseconds (pattern-based) or seconds (LLM-based). A human handles them in two minutes, and resents it.
Format-shaped checks (character limits, required disclaimers, JSON structure) are not Guardrails-node territory either, those belong in output parsers, Code nodes, or Custom Regex. But they share the same principle: if the rule is clear and context-free, do not waste a reviewer on it.
The pattern: if the check has a clear rule, applies the same way regardless of context, and the right answer does not require judgment, it belongs in the automated layer. Putting a human on it creates bottlenecks without adding value.
The Combined Pattern: Guardrails Before HITL
The architecture that works in production treats guardrails and HITL as sequential layers, not competing alternatives.
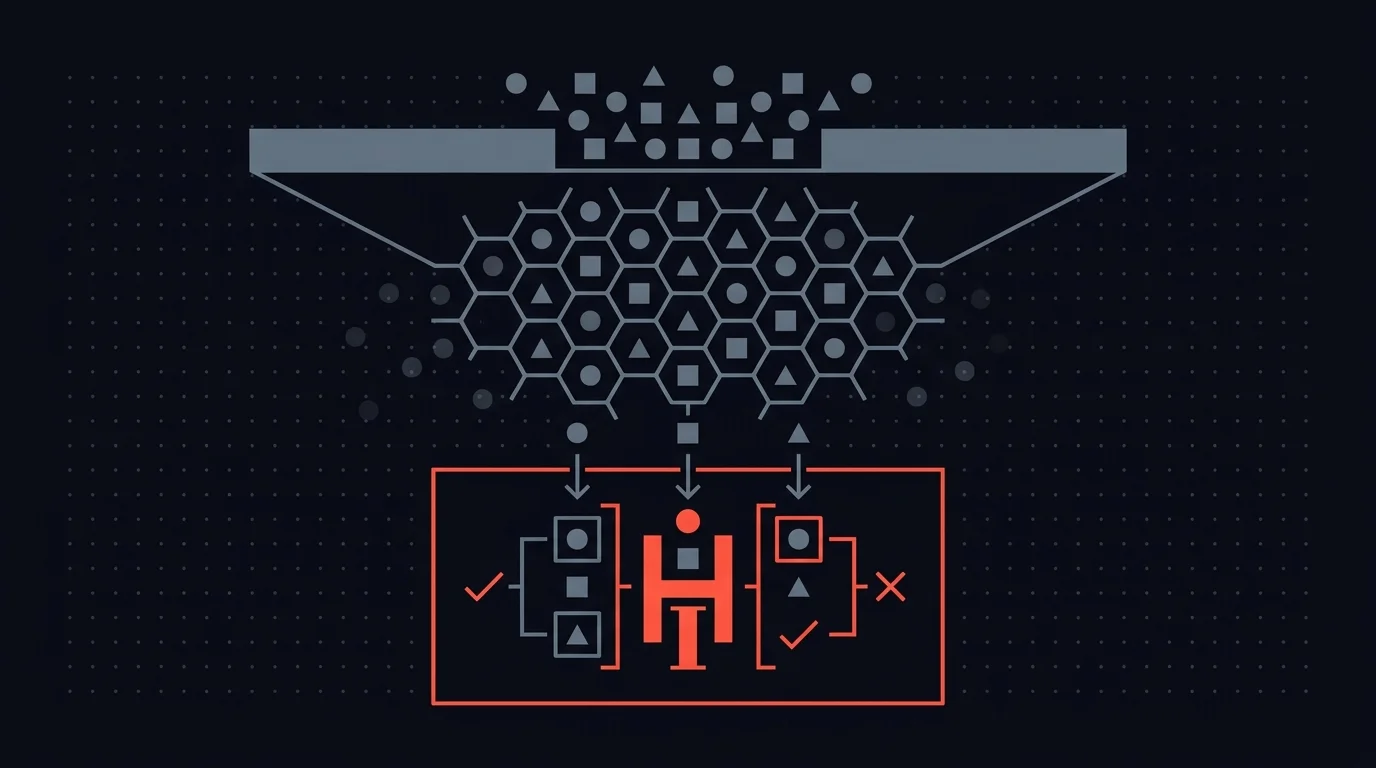
Layer 1: Guardrails (automated, fast, cheap). The AI generates output. Before any human sees it, the output passes through guardrail checks.
Profanity detected? Auto-rejected and looped back for regeneration. PII leaked? Sanitized automatically. Off-topic drift? Flagged and rerouted. Obvious violations never reach a reviewer.
Layer 2: HITL (human judgment, slower, high-value). Everything that clears the guardrails is structurally clean, no profanity, no PII, no policy violations. Now a reviewer evaluates the things guardrails cannot check. Is the tone right for this customer? Are the facts accurate? Does this make business sense?
This sequencing does two things that matter:
It reduces review volume. Some share of AI output trips a rule-based check: leaked PII, profanity, off-topic drift, banned-keyword matches. The exact percentage depends on the model, the prompt, and how strict your policies are, but every one of those items handled by a guardrail is one less mechanical check on a reviewer's queue. Guardrails filter them out so the human queue contains only outputs that genuinely require judgment.
It reduces reviewer fatigue. When a reviewer's queue is full of obvious issues, "this email contains a profanity," "this response mentions a competitor", they start skimming. They burn attention on low-value checks and have less focus left for the high-value decisions.
When guardrails handle the obvious violations, reviewers focus on judgment calls: the work that actually benefits from a human brain.
Practical Example: AI-Drafted Customer Responses
Here is what the combined pattern looks like in an actual n8n workflow for AI-drafted customer support responses.
Step 1: AI drafts the response. The AI agent node receives the customer inquiry, retrieves context (order history, account details, previous interactions), and generates a draft.
Step 2: Guardrails check. The draft passes through a Guardrails node configured with a Keywords list, PII detection, Topical alignment, and Custom Regex for the patterns that need it. A short Code node handles the response-length cap separately, since length is not a built-in guardrail.
Violations branch to regeneration with a corrective prompt, or rejection with a logged reason. Pattern-based checks return in milliseconds, LLM-based ones in a second or two. No human involved.
Step 3: Human review. Outputs that clear guardrails go to a reviewer who sees the draft alongside the customer's original message, account details, and relevant history. They approve, edit (fix a factual error, adjust tone, change an offer), reject with notes for regeneration, or escalate to a specialist.
Step 4: Send. Approved or edited responses go to the customer.
The exact share of outputs that guardrails catch will vary with your prompt quality, model, and policy strictness. In practice, a meaningful slice of AI output trips at least one rule-based check.
Those are responses a reviewer would have caught anyway, just slower and at higher cost. The reviewer spends their time where it counts: Is this response helpful for this specific customer? Is the information accurate against their actual account? Is the tone appropriate given their recent history?
When You Only Need One Layer
Not every workflow needs both layers.
Guardrails only works when the AI output is low-stakes and every failure mode is rule-catchable. Internal summaries, data enrichment, log categorization. If a guardrail catches the problem, a human review adds cost without adding value.
HITL only works when volume is low enough that a reviewer can look at everything, and the issues are judgment-based. A workflow processing five high-stakes decisions a day might skip guardrails because the reviewer is already reading every output carefully.
But for most production n8n workflows generating customer-facing content at meaningful volume, you end up needing both.
The Feedback Loop That Makes Both Layers Smarter
Neither guardrails nor HITL is set-and-forget. Every time a reviewer catches something, ask: could a guardrail have caught this instead? If the answer is yes, add the rule. Over time, your guardrails handle more of the mechanical checks and your reviewers spend less time on pattern-matching and more time on the judgment calls that actually need a human.
That is the whole point. Guardrails and HITL are not competing approaches. They are complementary layers, automated enforcement where rules work, human judgment where they do not. The combined pattern keeps the humans focused on the decisions that only humans can make.
Common Questions
Can guardrails replace human-in-the-loop entirely? Not for customer-facing workflows. Guardrails catch rule violations but cannot evaluate tone, verify facts against account data, or make business judgment calls. For low-stakes internal workflows (summaries, categorization), guardrails alone may be sufficient.
Can HITL replace guardrails entirely? A human can catch everything a guardrail catches. It just does not scale. At volume, reviewers burn attention on mechanical checks and have less focus for the judgment calls that actually need them.
How do I decide which checks belong in guardrails vs. HITL? Two questions. Can the check be stated as a clear, consistently applicable rule? Does the right answer depend on context, who the customer is, what happened previously, business considerations? If the rule is clear and context does not matter, it is a guardrail. If context matters, it is HITL.
Does the guardrails-before-HITL pattern add complexity to my workflow? A few nodes. The Guardrails node sits between your AI agent and the review step, with branches for violations and clean outputs. In practice, this is simpler than expecting reviewers to catch both rule violations and judgment calls.
Related guides
- Human-in-the-loop for n8n: complete guide — the HITL side in depth
- Why n8n AI agent workflows need human oversight — where judgment matters
- Audit trails for n8n AI agents — recording the decisions guardrails cannot make
If you are building n8n workflows where guardrails are not enough and a human needs to approve the write, Humangent is the approval control layer for n8n workflows — every high-risk action gets an owner, deadline, decision record, and audit trail before n8n writes into another system. Join the waitlist at humangent.io. Founding-team pricing for waitlist members.
Related Humangent resources
Humangent is for teams using n8n that need approval routing, escalation, multi-level sign-off, editable review fields, and a decision record before a workflow writes into another system.
The core pattern is simple: n8n sends the request, the reviewer sees the context, the reviewer chooses or edits the decision, and n8n resumes from a callback with a record attached. That keeps approval logic out of fragile Slack threads and makes the human decision visible to the team that owns the outcome.
These guides cover where to place human checkpoints, how to handle timeouts, when to route to another reviewer, what to record for audit, and when n8n built-in approval options are enough. The goal is practical workflow control for teams past the prototype stage.
For simple one-reviewer workflows, n8n built-in approval options can be enough. The need for a separate approval control layer shows up when several workflows compete for the same reviewers, when a backup reviewer needs to take over on a deadline, or when the team lead needs to reconstruct the decision after the workflow has already written to another system.
Humangent centers on that team operating model: one reviewer account across workflows, configurable routing, and a decision trail that belongs to the approval process. No scattered execution logs and chat-message archaeology.